Reviewing an SQL interview question
By Amit Grinson in R
August 31, 2021
Introduction
During the first half of 2021, as I was finishing up my M.A. thesis, I started searching for a job in Data Analytics. My journey into analytics was through learning R and I realized I had to learn some SQL, or at least familiarize myself with it.
Fast forward to interviewing, and most of the SQL interview questions were relevant and interesting, with one question particularly motivating further thoughts; this blog post details that question and several answers to it.
The question and data have no connection my current employer. The data used here is made up and the question came from a different company altogether.
I’ll be using R to setup a local SQL connection but power through the blog post with actual SQL code. While not necessary, some SQL knowledge is useful to understanding the various answers’, and more so the syntax.
The Interview question
So here it goes:
Let’s say you have a table of users’ payments. The table has the user’s name, date of payment and the amount they received. Users have multiple records with different amounts and dates. For each user, return: the user name, the maximum amount they received and the date of that payment.
Once you solve that, solve it again using a different approach.
For a more practical example, consider the following raw data:
| username | payment_date | amount |
|---|---|---|
| Tom | 2021-05-11 | 75 |
| Danny | 2021-05-12 | 62 |
| Alice | 2021-05-12 | 85 |
| Alice | 2021-05-29 | 72 |
| Danny | 2021-06-12 | 87 |
| Alice | 2021-06-24 | 45 |
| Tom | 2021-06-28 | 80 |
| Alice | 2021-07-03 | 60 |
| Danny | 2021-07-05 | 42 |
| Tom | 2021-07-12 | 56 |
| Tom | 2021-07-19 | 95 |
| Danny | 2021-08-01 | 80 |
Return the following table (rows highlighted in light green):
| username | payment_date | amount |
|---|---|---|
| Alice | 2021-05-12 | 85 |
| Danny | 2021-06-12 | 87 |
| Tom | 2021-07-19 | 95 |
So we know what we have to do. Before we do it, let’s see how not to do it.
✖ Why not just GROUP BY? ✖
If you’re new to SQL, an immediate question that might come to mind is why not use a GROUP BY for the UserName, date and select the MAX value. In other words, just filter each observation by the max value according to one of the variables.
The issue is that when we use GROUP BY we retrieve the information that is already aggregated. That is, if we group by the seller name and the payment date when we select the max, then we’ll get the value for each distinct user and date:
SELECT UserName,
payment_date,
MAX(amount) AS amount
FROM Payments
GROUP BY UserName, payment_date
Alternatively, if we GROUP BY the UserName and SELECT the MAX value and the date, the result will depend on the Relational Database Management System (RDBMS) you use In MySQL, we might get the information for each User, their max value and some date (here the top date value), but not the correct date! In SSMS I’m using we’ll get an error since we select a column that’s not contained in an aggregate function, nor in the GROUP BY clause:
SELECT UserName,
payment_date,
MAX(amount) as Amount
FROM payments
GROUP BY UserName
## Error: nanodbc/nanodbc.cpp:1655: 42000: [Microsoft][ODBC SQL Server Driver][SQL Server]Column 'payments.payment_date' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause. [Microsoft][ODBC SQL Server Driver][SQL Server]Statement(s) could not be prepared.
## <SQL> 'SELECT UserName,
## payment_date,
## MAX(amount) as Amount
## FROM payments
## GROUP BY UserName'
So How do we solve this? Let’s dive in.
Solutions
1. Window functions
The first solution that might come to mind is using a Window function. If you don’t know window functions I suggest you familiarize yourself with their abilities. To borrow from PostgreSQL’s description, a window function “performs a calculation across a set of table rows that are somehow related to the current row”. In contrast to aggregate operations (sum, avg, etc), using window functions doesn’t cause rows to become grouped into single row outputs.
We can use the window function DENSE_RANK()/RANK()1 to retrieve the rank of each amount for each user, and extract the relevant row with an outer query:
SELECT UserName, Payment_Date as 'Payment Date', amount
FROM (
SELECT *,
DENSE_RANK() OVER(Partition BY UserName Order by amount DESC) as rnk
FROM payments) AS ranked_table
WHERE rnk = 1
| UserName | Payment Date | amount |
|---|---|---|
| Alice | 2021-05-12 | 85 |
| Danny | 2021-06-12 | 87 |
| Tom | 2021-07-19 | 95 |
Table 1: 3 records
OK, that was pretty straight forward. But the interview question doesn’t end there but asks for another approach. Let’s move on.
2. Self Join
JOIN are key functions when querying data. Considering the large amount of data a company has, and the normalization procedures it does you’ll be expected to join a lot. In this specific case we can leverage the arithmetic features of a JOIN to retrieve the relevant value:
SELECT DISTINCT p.UserName, p.payment_date, p.amount
FROM payments p
LEFT JOIN payments pp ON p.UserName = pp.UserName
AND p.amount < pp.amount
WHERE pp.amount IS NULL;
While we’re all familiar with ‘regular’ * JOIN using an equality sign =, we can check for other operations such as smaller than <. Essentially we do a cartesian join of the table on itself by UserName, and match rows where values (p.amount) are smaller than other values in the table we join on (pp.amount). Our max value won’t find any relevant rows to join, considering it’s not smaller than anything, which will result in a NULL value we can use to filter.
We can also explore the intermediate step of the above-code by looking at one of the users’ observations:
SELECT top 3 p.UserName,
p.payment_date,
p.amount,
pp.amount as amount2
FROM payments p
LEFT JOIN payments pp ON p.UserName = pp.UserName
AND p.amount < pp.amount
WHERE p.UserName = 'Danny'
ORDER BY p.amount DESC
| UserName | payment_date | amount | amount2 |
|---|---|---|---|
| Danny | 2021-06-12 | 87 | NA |
| Danny | 2021-08-01 | 80 | 87 |
| Danny | 2021-05-12 | 62 | 80 |
Table 2: 3 records
As we can see from the top 3 observations (though 7 are returned per user), values that are not smaller than other values, i.e. our max value, return a null value we can use to filter. If you want to explore it more just copy the above code to the snippet example, remove the WHERE clause and also select pp.amount.
3. Correlated subquery
We’ve come to my final approach for this blog post. I’ve come to appreciate correlated subqueries since learning them, as I find them somewhat similar to vectorized operations in R such as the apply family and the purrr library.
A correlated subquery is a row-by-row process, in which each subquery is executed once for the outer query (adapted from GeeksforGeeks). Let’s look at the code and explain it more clearly:
SELECT UserName,
Payment_Date,
amount
FROM Payments p
WHERE amount = (SELECT MAX(amount)
FROM Payments pp
WHERE pp.UserName = p.UserName) -- Notice the relation to the parent table
| UserName | Payment_Date | amount |
|---|---|---|
| Tom | 2021-07-19 | 95 |
| Danny | 2021-06-12 | 87 |
| Alice | 2021-05-12 | 85 |
Table 3: 3 records
To easily read the query and understand correlated subqueries, let’s start from the inside. From the payments tables where the UserName is equal to the UserName in the outer query, grab the maximum amount. Now the outer query goes row by row for each user and compares whether that row’s amount is equal to that user’s max amount, which is retrieved from the inner query.
And there we have it, three different approaches to the same problem.

Benchmarking
A question that arose for me is, for this specific case, which method is faster? Let’s try and answer it using a bit larger dataset:
glimpse(payments_big)
## Rows: 2,000
## Columns: 3
## $ username <chr> "Alice", "Alice", "Alice", "Danny", "Tom", "Danny", "Tom"…
## $ payment_date <date> 2018-01-20, 2021-01-02, 2018-08-10, 2019-04-19, 2019-08-…
## $ amount <int> 7877, 2593, 9887, 6806, 4793, 5910, 6052, 3493, 8524, 132…
A total of 2,000 rows for all the three users. Now, let’s benchmark using The R package {sqldf} which passes the SQL statements to a temporally created database:
benchmarking <- microbenchmark::microbenchmark("Window" = sqldf(Window_script),
"Join" = sqldf(Join_script),
"Correlated subquery" = sqldf(Correlated_subquery_script),
unit = "ms")
Finally, let’s explore the benchmarking scores:
| approach | min | 25% | mean | median | 75% | max | N |
|---|---|---|---|---|---|---|---|
| Window | 14.2 | 15.4 | 18.3 | 16.6 | 18.7 | 43.4 | 100 |
| Join | 102.4 | 108.4 | 132.1 | 120.0 | 146.3 | 325.8 | 100 |
| Correlated subquery | 294.6 | 310.8 | 370.4 | 354.9 | 416.2 | 575.6 | 100 |
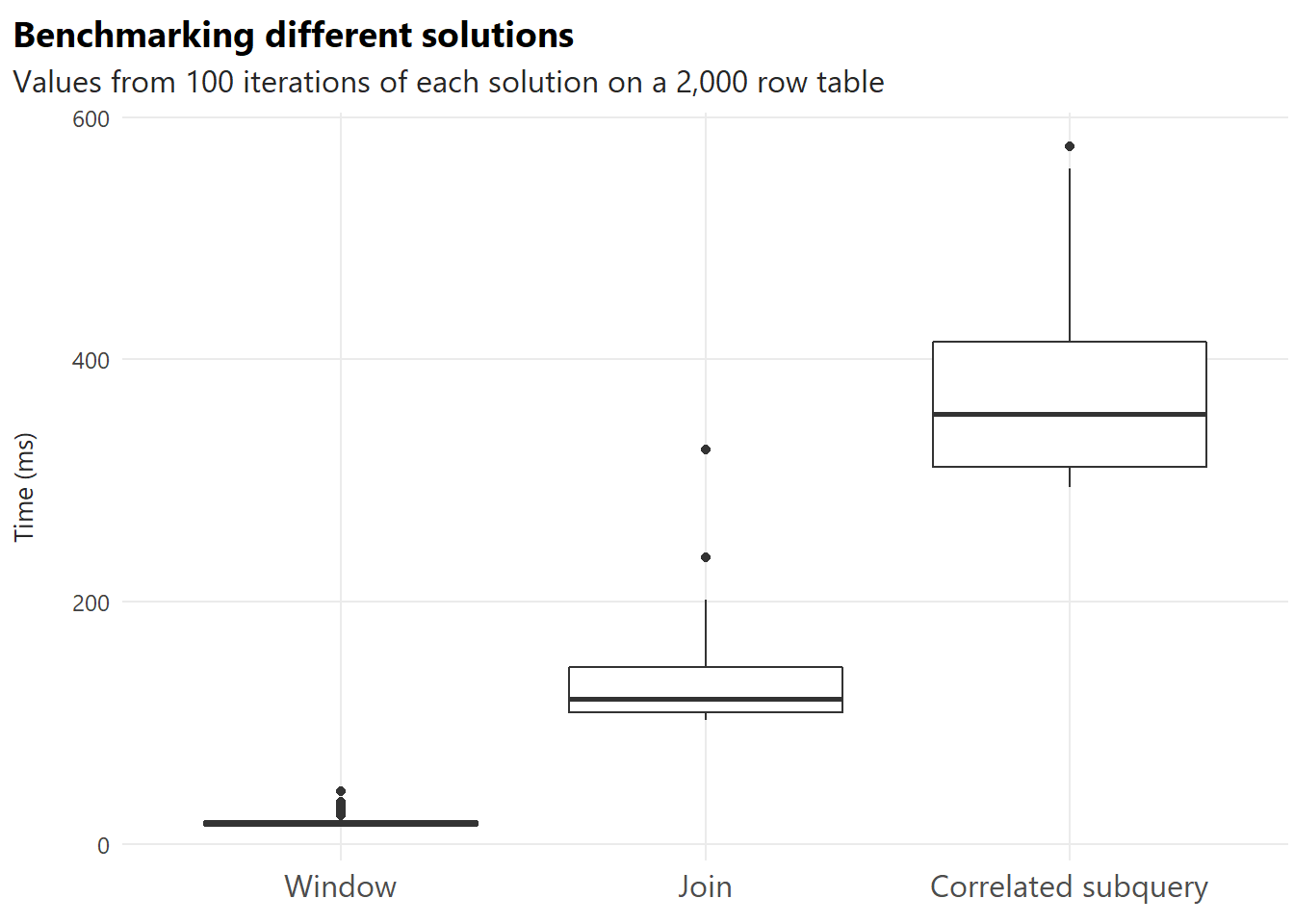
One caveat is that some noise might have occurred when I queried the data: Since we used the {sqldf} R package to benchmark, the table is loaded to a temporarily created database and the SQL statement is run on it. With that said, I imagine that if would have caused some issues, it would have done so across all statements.
As to our results, we can see that for the current question, the window function is most efficient. I think it’s also the most friendly for beginners and commonly used.
However, I believe that knowing all approaches can help you write better SQL. That is, sometimes one approach is a better fit to a specific use-case. I definitely wrote a correlated subquery at work as it was the best fit at the time (in terms of readability and as an immediate answer), so though it’s least efficient here I’m sure it’s worth knowing.
Closing remarks
This was a pretty short post on some SQL approaches to solving a question. You can probably think of different approaches, or variants of the current ones. When contemplating this question I felt that it required me to utilize different SQL functions to solve the same question, so overall I’m glad I came across it. I didn’t get the job but that’s OK. Eventually that’s how I ended up where I am today :)
Hope you find this useful and learned something new. Feel free to reach out and let me know of other solutions you thought of!
-
One reason I’m not going for ROW_NUMBER here is that were interested in the top value that could have multiple appearances for a user. ROW NUMBER will only give us one value, here I’m interested in the max value that could appear several times. ↩︎